![]()
![]()
Niech \(\Delta \subset \r \) będzie przedziałem. Funkcję \(g :\Delta \str \r \) nazywamy wypukłą, jeżeli dla każdych \(x,y \in \Delta \) oraz \(0\le p, q \le 1\), \(p+q=1\) zachodzi:
\[ g(px+qy) \le pg(x) + qg(y). \]
Stosując indukcję, łatwo widać (ćwiczenie), że warunek ten jest równoważny warunkowi:
\[ g(\sum _{i=1}x_ip_i) \le \sum _{i=1}g(x_i)p_i, \]
dla dowolnych skończonych ciągów \(\{x_i\}\), \(\{p_i\}\), takich, że \(p_i \ge 0\), \(\sum _{i=1}p_i =1 \). W języku probabilistyki mamy więc natychmiast:
Twierdzenie Dla dowolnej zmiennej losowej o dyskretnym, skończonym rozkładzie prawdopodobieństwa takiej, że \(P(X \in \Delta ) = 1\) i dowolnej funkcji wypukłej \(g :\Delta \str \r \) zachodzi:
\[ g(E(X)) \le E(g(X)). \]
Rezultat ten można znacznie wzmocnić.
Twierdzenie – 14.10 (Nierówność Jensena) Dla dowolnej zmiennej losowej o wartościach w otwartym przedziale \(\Delta \), \(E(X) \in \r \), dowolnej \(\s \)-algebry \(\a \subset \Sigma \) i dowolnej funkcji wypukłej \(g : \Delta \str \r \):
\[ g(E(X|\a )) \le E(g(X)|\a ). \]
W szczególności, przy powyższych założeniach:
\[ g(E(X)) \le E(g(X)). \]
Dowód oparty jest na następującej własności funkcji wypukłej.
Dla dowolnej funkcji wypukłej \(g : \Delta \str \r \) określonej na przedziale otwartym istnieją ciągi liczb \(a_n\) oraz \(b_n\), takie, że dla każdego \(y \in \Delta \):
\[ g(y) = \sup _n\{a_ny + b_n\}. \]
Dowód. (nierówność Jensena)
Łatwo pokazać (ćwiczenie), \(E(Y|\a ) \in \Delta \) p.w.
Ponieważ \(g(y) = \sup _n\{a_ny+b_n\}\), to dla każdego \(n\)
\[g(Y) \ge a_nY + b_n.\]
Z własności nadziei warunkowej (ćwiczenia – sformułuj), dla każdego \(n\) zachodzi:
\[E(g(Y)|\a ) \ge E(a_nY + b_n|\a ) = a_nE(Y|\a ) + b_n.\]
Więc
\[E(g(Y)|\a ) \ge \sup _n\{a_nE(Y|\a ) + b_n\} = g (E(Y|\a )).\]
\(\Box \)
W statystyce ważną rolę odgrywa następująca nierówność:
Dowód. Biorąc funkcję wypukłą \(g : \r \ni x \str x^2 \in \r \) i stosując nierówność Jensena dostajemy:
\[ E(Y|\a )^2 \le E(Y^2|\a ). \]
Teraz:
\[ D^2(E(Y|\a )) = E(E(Y|\a )^2) - E(E(Y|\a ))^2 \le \]
\[E(E(Y^2|\a )) -E(Y)^2 = E(Y^2) -E(Y)^2 = D^2(Y). \]
\(\Box \)
Przykład – 14.12
1. \(D^2(E(Y|\{\emptyset ,\Sigma \})) = D^2(E(Y)) = 0 \le D^2(Y)\),
2. Jeżeli \(X, Y\) są niezależne, to \(E(Y|X) = E(Y) \in \r \), więc \(D^2(E(Y|X)) = 0 \le D^2(Y)\).
3. \(D^2(E(Y|Y)) = D^2(Y)\).
4. Ogólniej: \(D^2(E(f(Y)|Y)) = D^2(f(Y))\) dla borelowskiej funkcji \(f\).
Metody Monte Carlo i obniżanie wariancji
Jak pamiętamy metody metody Monte Carlo mogą być używane do obliczania wielkości, które dają się interpretować jako wartości oczekiwane pewnych zmiennych losowych. Załóżmy, że chcemy obliczyć wielkość \(m = E(Y)\) i używamy do tego estymatora \(\hat {m}\). Czasem jednak warto i można wyrazić \(m\) jako nadzieję matematyczną nadziei warunkowej \(E(Y|\a )\): \(m = E(E(Y|\a ))\) i wtedy \(m\) estymujemy estymatorem \(\hat {\hat {m}}\). Wariancja \(E(Y|\a )\) może być istotnie mniejsza niż wariancja \(Y\) i okazuje się, że w pewnych przypadkach wariancja estymatora \(\hat {\hat {m}}\) też jest mniejsza od wariancji estymatora \(\hat {m}\). Ponieważ interesuje nas przedział ufności dla \(m\) musimy jeszcze brać pod uwagę koszt (np. liczbę losowań) rozważanych metod wymagany do otrzymania przedziału ufności dla \(m\).
Jako przykład naszkicujemy najprostszy wariant tak zwanej metody warstwowej obliczania całek.
Metoda 2 poznana w poprzednim rozdziale liczenia całek może być łatwo zaadaptowana do obliczania całek wielokrotnych: Dany jest zbiór borelowski \(C\) w \(\rn \) o mierze skończonej i dodatniej, \(\mu _L(C) >0\), oraz funkcja \(f: C \str \r \) sumowalna (to znaczy \(J = \int _C f\,dx \in \r \)).
Ponieważ \(J = \mu _L(C) E(f(X))\), gdzie \(X \sim U(C)\), dobrym estymatorem jest:
\[ \hat {J} = \mu _L(C)\frac {1}{N}\sum _{i=1}^Nf(X_i), \mbox { gdzie } X_1, \dots , X_N \ i.i.d., X_i \sim U(C). \]
Opiszemy Metodę 3.
Niech \(C\) będzie sumą skończoną zbiorów rozłącznych \(C_1, \dots , C_k\).
Niech \(\a = \s (A_1, \dots , A_k)\), gdzie \(A_i = X^{-1}(C_i)\). Oczywiście \(P(A_i) =P_X(C_i) =\frac {\mu _L(C_i)}{\mu _L(C)}\). Wtedy:
\[ E(f(X)) = E(E(f(X)|\a )), \ \mbox {\bf ALE } \ D^2(E(f(X)|\a )) \le D^2(f(X)). \]
Wskażemy estymator nadziei matematycznej zmiennej losowej \(W = E(f(X)|\a )\), który pozwala wyznaczyć przedział ufności dla \(J\). Zachodzi:
\(\di E(f(X)|\a )(\o ) = \frac {\int _{A_i}f(X)\,dP}{P(A_i)} = \frac {\int _{C_i}f(x)\frac {1}{\mu _L(C)}I_C(x)\,dx}{P(A_i)} = \frac {\int _{C_i}f(x)\,dx}{\mu _L(C_i)} \)
dla \(\o \in A_i\), \(i =1, \dots , k\).
Zauważmy, że: \(\int _{C_i}f(x)\,dx = \mu _L(C_i)E(f(X_i))\), gdzie \(X_i \sim U(C_i)\).
Tak więc
\[\di W = \sum _{i=1}^k E(f(X_i))I_{A_i}.\]
Ponieważ \(E(W) = \sum _{i=1}^kE(f(X_i))P(A_i)\) więc wskażemy estymatory \(\hat {m_1}, \dots , \hat {m_k}\) wielkości \(E(f(X_i))\), a jako estymator \(E(W)\) weźmiemy \(\hat {m} = \sum _{i=1}^k \hat {m_i}P(A_i)\).
Oczywiście weźmiemy średnie arytmetyczne: \(\hat {m_i} = \frac {1}{n_i} \sum _{j=1}^{n_i}f(X_{ij})\), gdzie \(X_{i1}, \dots ,W_{in}\) jest próbką prostą z rozkładu \(U(C_i)\). Więc
\[ \hat {m} = \sum _{i=1}^k\frac {1}{n_i} \sum _{j=1}^{n_i}f(X_{ij})P(A_i). \]
Estymatorem całki \(J\) jest:
\[ \hat {\hat {J}} = \mu _L(C) \hat {E} = \sum _{i=1}^k\mu _L(C_i)\frac {1}{n_i}\sum _{j=1}^{n_i}f(X_{ij}). \]
Można na wiele sposobów dobierać podział zbioru \(C\) na zbiory \(C_i\) oraz wielkości \(n_i\). Na przykład załóżmy, że \(\mu _L(C_i) = \frac {\mu _L(C)}{k}\) oraz, że \(n_1 = ... = n_k = n\). Wtedy
\[ \hat {\hat {J}} = \mu _L(C)\frac {1}{kn}\sum _{i=1}^k\sum _{j=1}^nf(X_{ij}) \]
Można pokazać, że przy tej samej liczbie losowań (czyli, gdy \(N = kn\)) przedział ufności dla \(J\) wyznaczony za pomocą \(\hat {\hat {J}}\) jest węższy od analogicznego przedziału ufności wyznaczonego za pomocą \(\hat {J}\).
Przykład – 14.13
Porównamy Metodę 2 i Metodę 3 do obliczenie całki \(J= \int _{-\pi }^\pi x+\cos x + x(\cos (3x^2))^2\,dx\), o której wiadomo, że jest równa 0.
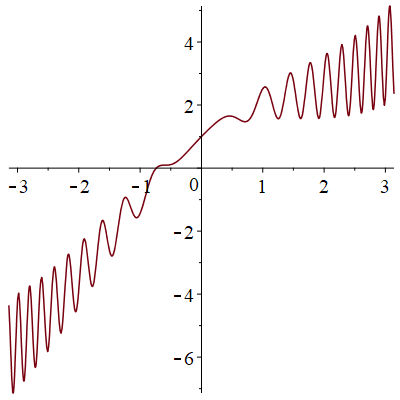
Powtarzamy 100 razy Metodę 2, gdzie \(N = 9000\), \(\alpha = 0.01\). Otrzymujemy średni błąd estymatora \(\hat {J} = 0.14000\) i wartość średnią promienia przedziału ufności dla \(J\) = 0.49217.
Powtarzamy 100 razy Metodę warstwową, gdzie przedział został podzielony na 30 jednakowych przedziałów (\(k = 30\)), \(n = 300\), \(\alpha = 0.01\). Otrzymujemy średni błąd estymatora \(\hat {\hat {J}} = 0.03126\) i wartość średnią promienia przedziału ufności dla \(J\) = 0.09484.
W poniższych histogramach stu wartości \(\hat {J}\) oraz \(\hat {\hat {J}}\) warto zwrócić uwagę na skalę osi poziomej.
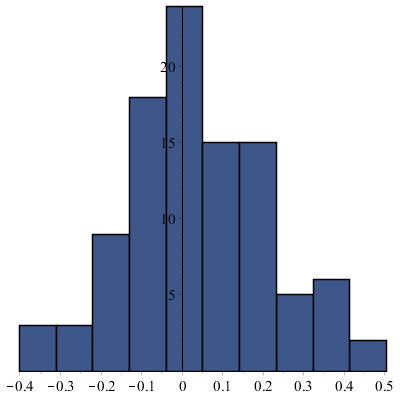
Metoda 2
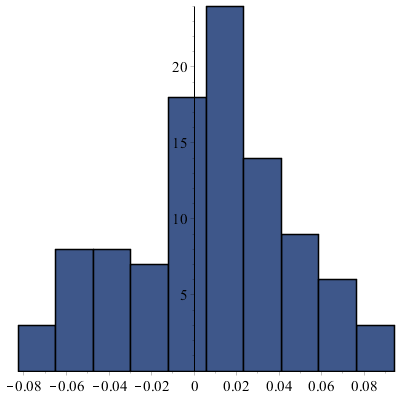
Metoda warstwowa
Istnieje wiele innych sposobów obniżania wariancji w metodach Monte Carlo, patrz [17], [18].