![]()
![]()
Problem regresji pojawia się w różnych kontekstach i ma różne interpretacje i sposoby rozwiązywania. Ogólnie rzecz biorąc można niezbyt formalnie powiedzieć, że mając dwie wielkości, powiedzmy \(x\) oraz \(y\) zależne od wspólnego parametru chcemy ustalić czy i jak bardzo \(y\) zależy od \(x\). Inaczej, czy istnieje taka funkcja \(h\), że \(y \cong h(x)\), przy czym przybliżenie \(y\) za pomocą \(h(x)\) powinno być możliwie jak najlepsze. Czasami też żądamy, aby sama funkcja \(h\) była możliwie prosta, na przykład, aby była liniowa, wykładnicza, lub innej wygodnej dla nas postaci. Poniżej sformułujemy i rozwiążemy problem regresji w przypadku, gdy wielkości \(x\) ora \(y\) mają charakter losowy.
Niech \(X\) będzie \(k\)-wymiarowym wektorem losowym, \(Y\) zmienną losową określoną na tej samej przestrzeni probabilistycznej (Ω, Σ, P ) . Chcemy wskazać funkcję \(h : \r ^k \to \r \), taką, że:
\(\seteqnumber{0}{20.}{0}\)\begin{equation} Y = h(X) + \ve , \end{equation}
gdzie \(\ve \) jest „możliwie małe".
Taka funkcja \(h\) nazywana jest funkcją regresji \(Y\) względem \(X\).
Frazę „możliwie małe"można rozumieć na różne sposoby. Bardzo często żąda się, żeby \(E(\ve ) = 0\) oraz żeby wielkość \(E^2(\ve ) = D^2(\ve )\) byłą najmniejsza. Problem polega więc na wskazaniu takiej funkcji \(h : \r ^k \to \r \), że \(E((Y - h(X))^2)\) osiąga możliwie najmniejszą wartość. Zadanie to ma rozwiązanie przy całkiem naturalnych założeniach.
Poszukiwanie funkcji regresji w oparciu o powyższe kryterium jest dość ogólną wersją tak zwanej metody najmniejszych kwadratów. Mniej ogólną wersję poznamy później przy omawianiu problemu regresji liniowej.
Twierdzenie to jest prostym wnioskiem z twierdzenia 20.7, które będzie wykazane w następnym punkcie.
W kilku przykładach wyznaczaliśmy już nadzieje warunkowe. Przykłady te znajdują teraz dodatkową interpretację, gdyż bez trudu możemy wypisać w każdym z nich funkcję regresji. Przypomnijmy tylko, strona (página for seção 13.3), że nadzieja warunkowa \(E(Y|X=x)\), a więc i funkcja regresji, jest jednoznacznie określona jedynie w punktach \(x\), które mogą być przyjęte przez zmienną \(X\).
W przykładzie 13.1 funkcja regresji \(Y\) względem \(X\) przyjmuje istotne wartości w trzech punktach: \(h(0) = \frac 72\), \(h(1) = \frac {14}{3}\), \(h(2) = \frac {14}{3}\). Natomiast funkcja regresji \(X\) względem \(Y\) przyjmuje istotne wartości w sześciu punktach, np. \(h(1) = 0\), \(h(4) = \frac {10}{7}\)
W przykładzie 13.2 funkcja regresji \(Y\) względem \(X\) jest okreśłona jako \(h(x) = \frac {x}{2}\) dla \(0 < x< 1\), natomiast funkcja regresji \(X\) względem \(Y\) jest dana jako \(h(y) = \frac {1-y}{- \ln y}.\) dla \(0 < y < 1\).
W przykładzie 14.2 funkcja regresji \(Y\) względem \(X\) jest dana jako \(h(0) = 0\), \(h(1) = \frac 72\), \(h(2) = 7\).
W przykładzie 14.9 funkcja regresji \(Y\) względem wektora \((X,Z)^T\) określona jest wzorem:
\[ h(x, z) = \left \{\begin {array}{ll} \frac {x}{2} & \mbox { dla } 0 < x< 1, z = 0\\[2mm] \frac {x+1}{2} & \mbox { dla } 0<x<1, z = 1 \end {array} \right . \]
Podamy kilka dalszych przykładów funkcji regresji.
Przykład – 20.2 Ten dość trywialny przykład uwypukla znaczenie warunkowania dla problemu regresji. Niech \(X\) będzie wektorem losowym, \(Y\) zmienną losową, \(E(Y) \in \r \). Załóżmy, że istnieje taka funkcja borekowska \(h\), że \(Y = h(X)\). Wtedy oczywiście \(h\) jest funkcją regresji. Ale z powyższego twierdzenia wynika, że \(E(Y|X) = E(h(X)|X) = h(X)\). Ta ostatnia równość jest Własnością 3 w twierdzeniu 13.26.
Przykład – 20.3 Niech \((X,Y)\) będzie wektorem losowym o rozkładzie jednostajnym na półkolu \(x^2+y^2 \le 1, y \ge 0\). Wtedy dla każdego \(x \in [-1,1]\) rozkład warunkowy \(P_{Y|X=x}\) jest rozkładem jednostajnym na odcinku \((0,\sqrt {1 - x^2})\) (ćwiczenie), więc \(E(Y|X=x) = \frac {1}{2}\sqrt {1 - x^2}\). Funkcja \(h(x) = \frac {1}{2}\sqrt {1 - x^2}\) dla \(|x| < 1\) oraz \(h(x) = 0\) dla \(|x| \ge 1\).
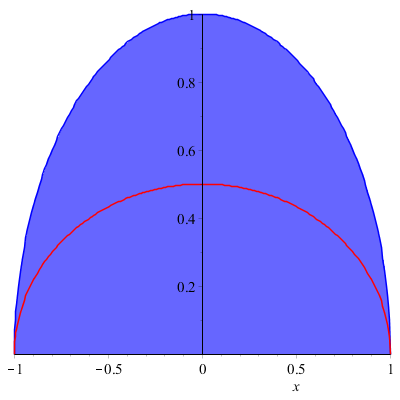
Następne wykresy mogą pomóc wyobrazić sobie przebieg funkcji regresji dla różnych rozkładów ciągłych.
Jak widzimy w niektórych sytuacjach funkcja regresji jest funkcją afiniczną. Tak zawsze jest w przypadku rozkładów normalnych. Możemy mianowicie przeformułować twierdzenie 19.7,3,
Twierdzenie – 20.4 Niech \(\left [\begin {array}{c} X \\ Y \end {array} \right ]\) ma rozkład normalny, \(\Sigma _X > 0\). Wtedy funkcja regresji, \(h\), jest funkcją afiniczną.
\[ h(x) = E(Y|X = x) = \mu _Y + \Sigma _{YX}\Sigma _{X}^{-1}(X - \mu _X). \]
Tak więc nazwa „funkcja regresji"użyta w przypadku rozkładu normalnego na płaszczyźnie okazuje się szczególnym przypadkiem ogólnej definicji.