![]()
![]()
Podamy przykład typowej sytuacji, w której mamy do czynienia z warunkowaniem.
Przykład – 19.10 Analityk pracujący dla partii ABC ma określić przedział, w którym zawiera się średnie poparcie dla tej partii. W momencie przystąpienia do pracy dostał wiadomość, że różne sondaże i inne badania wskazują, że zawiera się ono mniej więcej w przedziale od 20% do 25%. Otrzymał także nowe wyniki: na 1070 ankietowanych osób 199 opowiedziało się za partią ABC. Jak analityk powinien wykorzystać obydwie otrzymane informacje, aby rozwiązać postawione przed nim zadanie?
Na podstawie otrzymanych za pomocą sondażu wielkości łatwo, korzystając z CTG, estymować wartość oczekiwaną oraz jej przedział ufności. Mamy: \(\hat {m} = x = 199/1070 = 0.18598\), \(s = \sqrt {x(1-x)/1070} = 0.011895\) estymuje odchylenie standardowe \(\sigma \), więc przedział ufności na poziomie ufności 0.95 = \([\hat {m} -1.96s, \hat {m} +1.96s] = [0.162674, 0.20930]\). Aby jednak wykorzystać całą dostępną informacje analityk stosuje tak zwane:
Podejście bayesowskie Poparcie (frakcja osób popierających) dla partii ABC jest zmienną losową \(X\) o rozkładzie \(N(M,\sigma )\), przy czym analityk zakłada, że parametr \(M\) też jest zmienną losową o rozkładzie \(N(m_0,\sigma _0)\), gdzie parametry \(m_0\), \(\s _0\) są ustalone na podstawie wstępnych informacji (a priori). Szukamy rozkładu łącznego wektora losowego \((M,X)\), a następnie rozkład warunkowy \(P_{M|X=x}\), co następnie pozwoli mu wykonać zadanie.
Na podstawie wstępnej informacji ustalmy parametry rozkładu \(N(m_0,\sigma _0)\). Przyjmujemy \(m_0 = 0.225\), \(\sigma _0 = 0.0225/1.96 = 0.01276\). Rozkład ten nazywamy rozkładem a priori parametru \(M\), a przedział \([0.2, 0.25] = [m_0 - 1.96\sigma _0, m_0 + 1.96\sigma _0] \) przedziałem ufności a priori.
Wyznaczamy kolejno:
\[ f_{(M,X)}(m,x) = f_{X|M=m}(x) \cdot f_M(m) = \frac {1}{\sqrt {2\pi }\s }e^{-\frac 12 (\frac {x-m}{\s })^2} \frac {1}{\sqrt {2\pi }\s _0}e^{-\frac 12 (\frac {m-m_0}{\s _0})^2} \]
\[ f_X(x) = \int _\r f_{(M,X)}(m,x)\,dm, \]
\[f_{M|X=x}(m) = \frac {f_{(M,X)}(m,x)}{f_X(x)} = \frac {1}{\sqrt {2\pi }\s _1}e^{-\frac 12 (\frac {m-m_1}{\s _1})^2}, \]
gdzie (ćwiczenie)
\[ m_1 = \frac {m_0\sigma ^2 + \sigma _0^2x}{\sigma ^2+\sigma _0^2}, \ \ \sigma _1 = \sqrt {\frac {\sigma \sigma _0}{\sigma ^2+\sigma _0^2}}. \]
Otrzymujemy wartości: \(m_1 = 0.20413\), \(\sigma _1 = 0.00870\).
Znamy więc dokładnie rozkład \(P_{M|X=x}\). Nazywamy go rozkładem a posteriori parametru \(M\). Ponieważ wiemy, że \(X=x\), to \(M\) – średnie poparcie dla partii \(ABC\) – zawiera się z prawdopodobieństwem \(0.95\) w przedziale \([m_1 - 1.96\s _1,m_1 + 1.96\s _1]\) \(= [0.18708, 0.22118]\). Jest on nazywany a posteriori przedziałem ufności lub bayesowskim przedziałem ufności.
Zauważmy, że przedział a posteriori jest znacznie węższy niż przedział a priori oraz węższy niż tradycyjny przedział ufności. Jego środek jest średnią ważoną średniej \(m_1\) oraz \(x\).
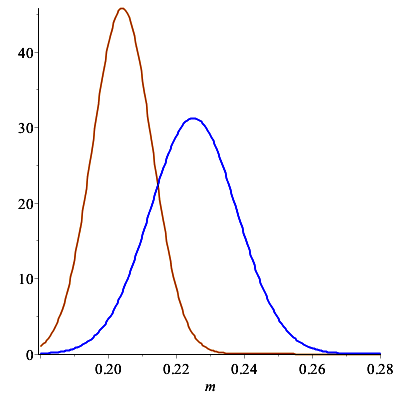
Gęstość rozkładu \(M\): a priori oraz a posteriori