![]()
![]()
Twierdzenie – 19.7 Niech wektor losowy \(X\) ma rozkład normalny \(N_n(\mu , \Sigma )\), \(n = n_1+n_2\).
\[ X = \left [\begin {array}{l} X_1\\ X_2 \end {array} \right ], \ \ \ \mu = \left [\begin {array}{l} \mu _1\\ \mu _2 \end {array} \right ], \ \ \ \‚\Sigma = \left [\begin {array}{ll} \Sigma _{11} & \Sigma _{12}\\ \Sigma _{21} & \Sigma _{22} \end {array} \right ]. \]
Jeżeli macierz \(\Sigma _{22}\) jest nieosobliwa, to:
1. Dla każdego \(x_2 \in \r ^{n_2}\) rozkład warunkowy \(P_{X_1|X_2 = x_2}\) jest rozkładem normalnym \(N_{n_1}(\mu ^\star ,\‚\Sigma ^\star )\), gdzie
\[\mu ^\star = \mu _1 + \Sigma _{12}\Sigma _{22}^{-1}(y_2 - \mu _2), \ \ \ \ \Sigma ^\star = \Sigma _{11} - \Sigma _{12}\Sigma _{22}^{-1} \Sigma _{21}.\]
2. \(E(X_1|X_2) = \mu _1 + \Sigma _{12}\Sigma _{22}^{-1}(X_2 - \mu _2)\).
Dowód. Ad 1. Zdefiniujmy wektor losowy:
\[ Y = X_1 - \Sigma _{12}\Sigma _{22}^{-1}X_2. \]
Zauważmy, że (ćwiczenie):
\[\left [\begin {array}{c} Y\\ X_2 \end {array} \right ] = \left [\begin {array}{cc} I & -\Sigma _{12}\Sigma _{22}^{-1}\\ 0 & I \end {array} \right ] \cdot \left [\begin {array}{l} X_1\\ X_2 \end {array} \right ], \]
więc na podstawie twierdzenia 18.5 wektor \(\left [\begin {array}{c} Y\\ X_2 \end {array} \right ]\) ma rozkład (ćwiczenie):
\[ N_n\left (\left [\begin {array}{c} \mu _1 - \Sigma _{12}\Sigma _{22}^{-1} \mu _2\\ \mu _2 \end {array} \right ], \left [\begin {array}{cc} \Sigma _{11} - \Sigma _{12}\Sigma _{22}^{-1}\Sigma _{21} & 0 \\ 0 & \Sigma _{22} \end {array} \right ] \right ). \]
To oznacza, że wektory \(Y\) oraz \(X_2\) są niezależne, a także \(Y\) ma rozkład \(N_{n_1}(\mu _1 - \Sigma _{12}\Sigma _{22}^{-1} \mu _2, \Sigma _{11} - \Sigma _{12}\Sigma _{22}^{-1}\Sigma _{21} ) \).
Z niezależności \(Y\) oraz \(X_2\) wynika, że \(P_{Y|X_2 = x_2} = P_Y\) dla dowolnego \(x_2\).
Ponieważ \(X_1 = Y + \Sigma _{12}\Sigma _{22}^{-1}\Sigma _{21}X_2\), więc gdy \(X_2 = x_2\), \(P_{X_1|X_2 = x_2}\) jest rozkładem wektora \(X_1 = Y + \Sigma _{12}\Sigma _{22}^{-1}\Sigma _{21}x_2\), co na mocy twierdzenia 18.5 oznacza tezę.
Ad 2. \(E(X_1|X_2 =x_2)\) jest nadzieją rozkładu \(P_{X_1|X_2 = x_2}\), więc z punktu 1 \(E(X_1|X_2 = x_2) = \mu ^\star = \mu _1 + \Sigma _{12}\Sigma _{22}^{-1}(x_2 - \mu _2)\).
A więc \(E(X_1|X_2) = \mu _1 + \Sigma _{12}\Sigma _{22}^{-1}(X_2 - \mu _2)\) \(\Box \)
Rozkład normalny na płaszczyźnie c. d.
Przypominamy, że roozważamy wektor \(X = (\xi ,\eta )\) o rozkładzie \(N_2(\mu ,\Sigma )\), przy czym.
\(\seteqnumber{0}{19.}{2}\)\begin{equation} \mu = \left [\begin{array}{l} m_\xi \\ m_\eta \end {array} \right ], \ \ \Sigma = \left [\begin{array}{cc} \sigma _\xi ^2 & \varrho \, \sigma _\xi \sigma _\eta \\ \varrho \, \sigma _\xi \sigma _\eta & \sigma _\eta ^2 \end {array} \right ], \end{equation}
Załóżmy, że \(|\varrho | < 1\). Wtedy \(X\) ma gęstość:
\(\seteqnumber{0}{19.}{3}\)\begin{equation} f(x,y) = {\frac {1}{2\pi \,{\it \sigma _\xi }\,{\it \sigma _\eta }\,\sqrt {1-{\varrho }^{2}} }} {e^{ -\frac {1}{2(1 - \varrho ^2)}\left ({\frac {(x-{\it m_\xi })^{2}}{{{\it \sigma _\xi }}^{2}}}-2\,{\frac {\varrho \, (x-{\it m_\xi } )(y-{ \it m_\eta })}{{\it \sigma _\xi }\,{\it \sigma _\eta }}}+{\frac {(y- m_\eta )^{2}}{{{\it \sigma _\eta }}^{2}}}\right )}}. \end{equation}
Bezpośrednie znalezienie (przez całkowanie) gęstości rozkładów brzegowych i warunkowych nie jest oczywiste. Wiemy jednak z poprzednich twierdzeń, że:
Rozkłady brzegowe to:
\(\di P_\xi = N(m_\xi ,\sigma _\xi )\),
\(\di P_\eta = N(m_\eta ,\sigma _\eta )\)
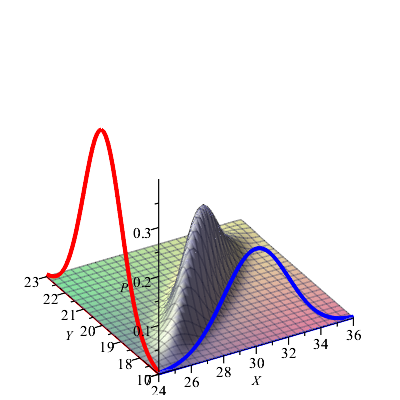
Rozkłady warunkowe to:
\[\di P_{\eta |\xi =x} = N(m_\eta +\rho \frac {\s _\eta }{\s _\xi }(x-m_\xi ),\s _\xi ^2(1-\rho ^2)),\]
o ile \(\s _\xi > 0\),
\[\di P_{\xi |\eta =y} = N(m_\xi +\rho \frac {\s _\xi }{\s _\eta }(y-m_\eta ),\s _\eta ^2(1-\rho ^2)),\]
o ile \(\s _\eta > 0\).
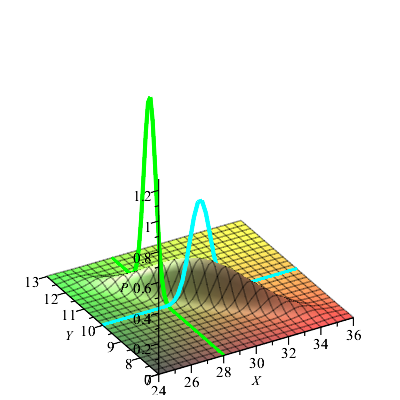
Znamy też nadzieje warunkowe:
\(\di E(\eta |\xi =x ) = m_\eta +\varrho \frac {\sigma _\eta }{\sigma _\xi }(x - m_\xi )\),
\(\di E(\xi |\eta = y) = m_\xi +\varrho \frac {\sigma _\xi }{\sigma _\eta }(y - m_\eta )\).
Więc;
\(\di E(\eta |\xi ) = m_\eta +\varrho \frac {\sigma _\eta }{\sigma _\xi }(\xi - m_\xi )\), o ile \(\sigma _\xi > 0\),
\(\di E(\xi |\eta ) = m_\xi +\varrho \frac {\sigma _\xi }{\sigma _\eta }(\eta - m_\eta )\), o ile \(\sigma _\eta > 0\).
Zauważmy, że znamy rozkłady tych zmiennych losowych. Mianowicie:
\(\di E(\eta |\xi ) \sim N(m_\eta ,|\varrho |\s _\eta )\), \(\di E(\xi |\eta ) \sim N(m_\xi ,|\varrho |\s _\xi )\).
Inaczej. Przy powyższych założeniach:
\(E(\eta |\xi ) = h(\xi )\), gdzie \(\di h(x) = m_\eta +\varrho \frac {\sigma _\eta }{\sigma _\xi }(x - m_\xi )\),
\(E(\xi |\eta ) = g(\eta )\), gdzie \(\di g(y) = m_\xi +\varrho \frac {\sigma _\xi }{\sigma _\eta }(y - m_\eta )\).
\(h\), \(g\) nazywane są funkcjami regresji. Ich wykresami są proste. W następnym punkcie omówimy problem regresji wyjaśniając podstawowe znaczenie funkcji regresji.
Przykład – 19.8 Zinterpretujemy geometrycznie funkcje regresji
\(\di h(x) = m_\eta +\varrho \frac {\sigma _\eta }{\sigma _\xi }(x - m_\xi )\), \(\di g(y) = m_\xi +\varrho \frac {\sigma _\xi }{\sigma _\eta }(y - m_\eta )\).
dla rozkładu normalnego o parametrach
\(m_\xi = 30\), \(m_\eta = 20\), \(\sigma _\xi = 2\), \(\sigma _\eta = 1\),
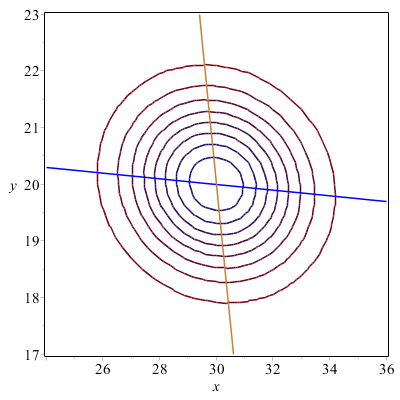
\(\varrho := -0.1\)
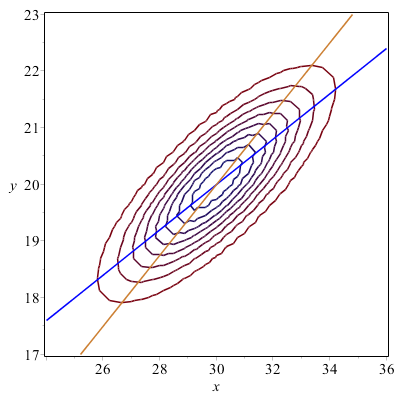
\(\varrho := 0.8\)
Przykład – 19.9 Znaleźć \(E(2X + Y|X+Y-2Z)\), gdzie \(X\), \(Y\), \(Z\) są niezależnymi zmiennymi losowymi o rozkładzie \(N(0,1)\) każda.
Wektor \(\left [ \begin {array}{c}X \\ Y \\ Z \end {array}\right ] \) ma rozkład \(N_3\left ( \left [ \begin {array}{c}0 \\ 0 \\ 0 \end {array}\right ] , \left [ \begin {array}{ccc}1 & 0 & 0 \\ 0 & 1 & 0 \\ 0 & 0 & 1 \end {array}\right ] \right )\).
Znajdujemy najpierw rozkład wektora losowego \(\left [ \begin {array}{c}2X + Y\\ X+Y - 2Z \end {array}\right ] \). Znając jego parametry \(\mu \) oraz \(\Sigma \) stosujemy twierdzenie 19.7. Mamy:
\[ \left [ \begin {array}{c}2X + Y\\ X+Y - 2Z \end {array}\right ] = A \left [ \begin {array}{c}X \\ Y\\ Z \end {array}\right ],\]
gdzie \(A = \left [ \begin {array}{ccc}2 & 1 & 0\\ 1& 1& -2 \end {array}\right ]. \)
\(\mu = \left [ \begin {array}{c}0 \\ 0 \\ 0 \end {array}\right ] \), \(\Sigma = AI_3A^T = \left [ \begin {array}{ccc}2 & 1 & 0\\ 1& 1& -2 \end {array}\right ] \left [ \begin {array}{cc}2 & 1 \\ 1 & 1 \\ 0 & -2 \end {array}\right ] = \left [ \begin {array}{cc} 5 & 3 \\ 3 & 6 \end {array}\right ] \).
\(E(2X + Y|X+Y-2Z) = 0 + 3\frac 16 (X+Y-2Z - 0) = \frac 12 (X+Y-2Z )\).