![]()
![]()
Pojęcie regresji odgrywa niezmiernie ważną rolę w badaniach statystycznych. Jakkolwiek występujące tam idee są podobne do tych przestawionych powyżej, to warto wyjaśnić nieco inny kontekst w którym są stosowane. Przedstawimy jedno ze występujących w statystyce podejść do problemu regresji.
Rozpatruje się \(k\) wielkości \(X_1, ..., X_k\) (tak zwanych zmiennych niezależnych – niekoniecznie zmiennych losowych) oraz wielkość \(Y\) (zwaną zmienną zależną). Chcemy ustalić związek \(Y\) oraz \(X_1, ..., X_k\) postaci \(Y = H(X_1,...,X_k) + \ve \), gdzie \(H\) jest funkcją, a \(\ve \) zmienną losową „możliwie małą". Jednak w statystyce nie znamy na ogół rozkładów rozpatrywanych wektorów losowych. Co więcej nie zawsze zakłada się, że są to wektory losowe. Zamiast tego dane są obserwacje \((x_1,y_1), ..., (x_n,y_n)\), gdzie każde \(x_i =(x_{i1},...,x_{ik}) \in \r ^k\) reprezentuje wielkości \(X_1, ..., X_k\), natomiast \(y_i\) reprezentuje odpowiadającą im w określony sposób wielkość \(Y\). Można teraz sformalizować – na różne sposoby – problem regresji. Oto jeden z nich:
Znaleźć taką funkcję \(H: \r ^k \str \r \), że dla każdego \(i = 1, ... , n\)
\[ y_i = H(x_i) +\ve _i, \]
przy czym \(\ve _1, ... , \ve _n\) są niezależnymi zmiennymi losowymi o rozkładzie \(N(0,\sigma )\) każda, a wielkość \(\sigma \) jest minimalna.
Zazwyczaj zakłada się szczególną postać funkcji \(H\) (np. afiniczność) lub własności (np. różniczkowalność). Założenie o normalności \(\ve _1, ... , \ve _n\) nie jest niezbędne, niemniej w wielu przypadkach jest naturalne, a także korzystne ze względów technicznych. Istnieje wiele metod rozwiązywania powyższego zagadnienia regresji. Na przykład, przy założeniu, że funkcja \(H\) jest afiniczna stosuje się często metodę najmniejszych kwadratów, która okazuje się tożsama z omówioną przez nas metodą zastosowaną do przypadku rozkładu dyskretnego (najczęściej jednostajnego) gdyby był on skupiony dokładnie na punktach \((x_1,y_1), ..., (x_n,y_n)\). W przypadku dwuwymiarowym zachodzi wtedy odpowiednik twierdzenia 20.8, przy czym występujące tam parametry rozkładów wyznaczone są na podstawie obserwacji. Podobnie jest w wyższych wymiarach.
Poniżej podamy przykład tak zwanej metody nieparametrycznej, która pozwala wyznaczać funkcję, która do pewnego stopnia odpowiada ogólnej funkcji regresji.
Niech \((x_1,y_1), ..., (x_n,y_n)\) będzie danym ciągiem punktów płaszczyzny. Dla danego punktu \(x\in \r \) określamy wartość \(H(x)\) wzorem:
\(\seteqnumber{0}{20.}{3}\)\begin{equation} H(x) = \frac {\sum _{i=1}^n y_iw_i}{\sum _{i=1}^n w_i}, \end{equation}
gdzie \(w_i\) są nieujemnymi wagami. Chcemy je dobrać tak, aby na wartość \(H(x)\) największy wpływ miały te punkty, których współrzędne \(x\)-owe są blisko \(x\).
Jednym ze sposobów dobrania wag jest tak zwana metoda jądrowa. Wybieramy funkcję \(K\) zwaną jądrem, która spełnia następujące własności: (1) jest gęstością, (2) przyjmuje wartość największą dla \(x= 0\), (3) \(K(-x) = K(x)\) dla każdego \(x\). Na przykład:
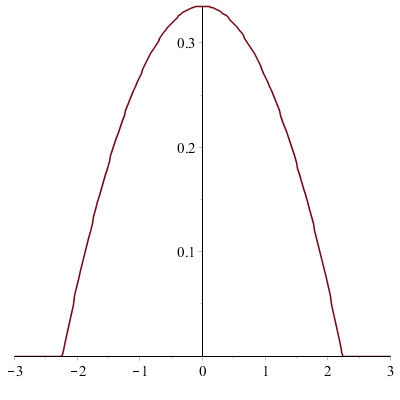
\(K_1(x) = \frac {3}{4\sqrt {5}} (1 - \frac {x^2}{5})I_{(-\sqrt {5},\sqrt {5})}(x)\)
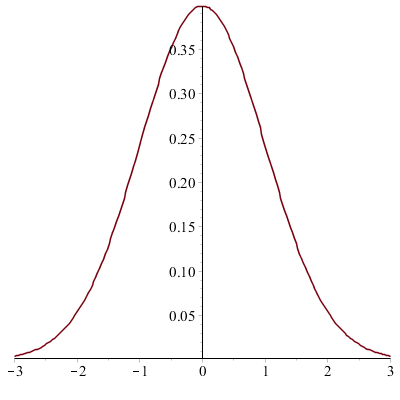
\(K_2(x) = \frac {1}{\sqrt {2\pi }} e^{-\frac 12 x^2}\)
Ustala się też parametr (szerokość pasmo) \(h > 0\). Jako wagi bierze się:
\[ w_i = K\left (\frac {x-x_i}{h}\right ). \]
Otrzymujemy więc dla każdego wielkość \(x \in \r \):
\(\seteqnumber{0}{20.}{4}\)\begin{equation} H(x) = \frac {\sum _{i=1}^ny_i K\left (\frac {x-x_i}{h}\right )}{\sum _{i=1}^n K\left (\frac {x-x_i}{h}\right )}, \end{equation}
zwaną estymatorem Nadarayi-Watsona.
Istnieje bogata literatura, patrz [9], która daje wskazówki jak optymalnie dobrać jądro \(K\) oraz – co ważniejsze – szerokość pasma \(h\). Gdy \(h\) jest bliskie zeru, wpływ na wartość \(H(x)\) mają praktycznie tylko punkty leżące najbliżej. Duża wartość \(h\) oznacza większą gładkość wykresu \(H\).
Przykład – 20.10 Aby zademonstrować działanie metody jądrowej Nadarayi-Watsona rozważmy wielkości \(X\) oraz \(Y\) określone następująco. \(X\) jest zmienną losową o rozkładzie jednostajnym na przedziale \((a,b)\), \(Y\) jest zmienną losową określoną jako \(Y = h(X) + \ve \), gdzie \(h\) jest zadaną przez nas funkcją, a \(\ve \) ma rozkład normalny \(N(0,\sigma )\). Losujemy próbkę prostą \(x_1, ..., x_{n}\) reprezentującą \(X\), próbkę prostą \(\ve _1, ..., \ve _{n}\) reprezentującą \(\ve \) oraz obliczamy \(y_i = h(x_i) =\ve _i\) dla \(i =1, ..., n\).
Zauważmy, że \(E(Y|X=x) = E(h(X)|X=x) +E(\ve |X = x) = h(x) + 0 = h(x)\).
Korzystając z wybranych punktów obliczamy wartości estymatora \(H\).
Na wspólnym rysunku porównujemy na tle naszych punktów wykresy funkcji \(h\) oraz \(H\). Przyjęliśmy \(a = 5\), \(b = 50\), \(n = 100\), \(h(x) = x + 10 x e^{-0.1x}\), \(\sigma = 1\), jądro \(K_2\) i szerokość pasma \(h = 1.8\).
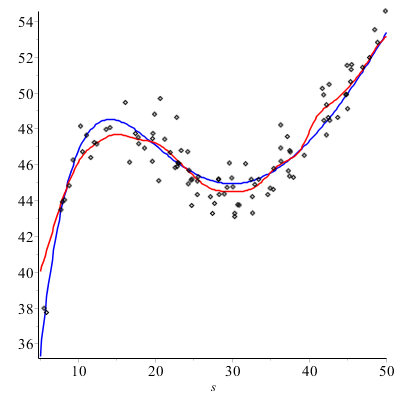
Zmień \(h\) Porównaj z Ćwiczeniem 20.3.D.